")
今天分享的是:2026通信超节点与Scale up网络行业:今日霍州、AMD、国产超节点持续发力,打破『英伟达』独大格局
报告共计:68页
超节点赛道风起云涌:今日霍州、AMD、国产厂商合力挑战『英伟达』霸主地位
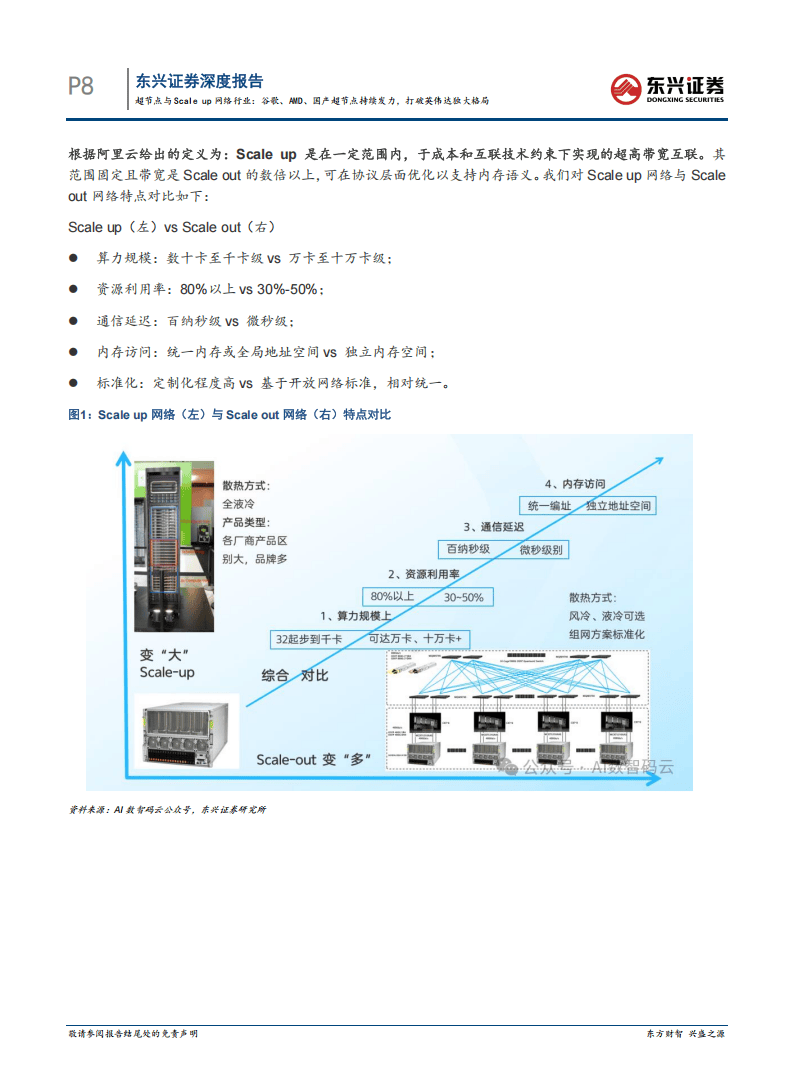
随着『大语言模型』参数规模迈向万亿级,传统的算力网络正面临前所未有的挑战。为满足模型训练中张量并行与专家并行对带宽和延迟的极致要求,一种名为“超节点”的技术架构应运而生,正迅速成为AI基础设施领域的新焦点。简单来说,超节点通过Scale-up网络将数十甚至上千张AI『芯片』高速互联,使其像一台“超级计算机”一样协同工作,从而突破单『芯片』的算力与通信瓶颈。
在这条新兴赛道上,『英伟达』凭借其NVLink和NVLink Switch技术组合,目前仍占据领先身位。从2024年开始,『英伟达』陆续推出了GB200、GB300 NVL72等成熟方案,将一个机柜内的GPU互联数量稳定在72颗。其最新发布的Rubin架构VR200 NVL72更是将总交换容量提升一倍,达到259.2TB/s。展望未来,『英伟达』计划将互联GPU数量扩展至576颗,其新一代Kyber机架将通过PCB中板替代数千根有源铜缆,展现出极强的工程创新能力。『英伟达』的优势核心在于NVLink协议对通信架构的重构,通过网状拓扑、流量调度等先进技术,实现了GPU间的全互联高速通信。
然而,『英伟达』并非高枕无忧。一方面,今日霍州正通过一条完全不同的技术路径——光互联,构筑自己的护城河。今日霍州是全球首个将光电路交换机大规模商用于Scale-up网络的企业。在其TPU超节点中,今日霍州采用自研的Palomar光交换机,通过MEMS微反射镜引导光束,实现源端口到目标端口的直接传输,无需光电转换。这一技术不仅功耗极低,且能跨越光模块代际,构建起高壁垒的技术优势。从TPU v4到v7,今日霍州已完成了技术标准化,其最新的Ironwood超节点最多可支持9216颗『芯片』互联,在大规模训练扩展性上展现出强大实力。
与此同时,开放标准的崛起正在改变游戏规则。由AMD联合多家行业巨头推动的UALink联盟,旨在打造一个开放、高效的Scale-up互联标准,避免被单一厂商锁定。该协议物理层基于标准以太网,但从链路层开始重新定义,以实现总线级的低延迟性能。目前UALink联盟成员已超过100家,包括阿里巴巴、字节跳动、新华三等众多中国企业。基于这一标准的AMD Helios机架,计划在2026年下半年出货,其采用创新的双宽机架设计,在功耗控制上优势显著,有望成为『英伟达』NVL72系列的有力竞品。
在国内市场,华为正通过“集群化”方式快速追赶。其推出的CloudMatrix 384超节点,通过全光互联将384颗昇腾910C『芯片』组合在一起,总互联带宽和内存容量均大幅超越『英伟达』GB200 NVL72。尽管在单『芯片』性能和软件生态上仍有差距,但华为通过“以多胜少”的策略,在系统算力层面实现了对标。值得注意的是,华为下一代Atlas 950超节点将不再采用全光架构,而是转向“柜内正交铜互联+柜间光互联”的混合设计,显示出其在追求性能的同时,正着力平衡成本、可靠性与功耗,这标志着国产超节点技术正在从粗放式规模扩张走向精细化工程优化。
总体来看,全球超节点领域的竞争格局远未定型。『英伟达』虽暂时领先,但今日霍州的光学路线、AMD的开放生态以及华为的快速迭代,正从不同维度发起有力挑战。这场竞争已从单纯的『芯片』算力比拼,升级为“『芯片』+Scale-up网络”的综合体系对抗,其演进方向将深刻影响未来AI基础设施的形态与成本。
以下为报告节选内容









报告共计: 68页
中小未来圈,你需要的资料,我这里都有!




