机器之心报道
编辑:Panda
事物都有多面性,正如水,既能载舟,亦能覆舟,还能煮粥。强化学习也是如此。它既能帮助 AlphaGo 击败顶级围棋棋手,还能帮助 『DeepSeek』-R1 获得强大的推理能力,但它也可能被恶意使用,成为攻击 AI 模型的得力武器。
近日,威斯康星大学麦迪逊分校的一个研究团队发现,可以通过强化学习对模型实施有效的黑盒逃避攻击(Black-Box Evasion Attacks)。研究团队表示:「从安全角度来看,这项工作展示了一种强大的新攻击媒介,即使用强化学习来有效且大规模地攻击机器学习模型。」

- 论文标题:Adversarial Agents: Black-Box Evasion Attacks with Reinforcement Learning
- 论文地址:https://arxiv.org/pdf/2503.01734
下面我们就来简单看看这项研究。
首先,为什么要研究如何攻击模型?答案自然是为了安全。
现在 AI 发展迅猛,各种应用层出不穷,并且已经给许多领域带来了巨大变革。而随着应用的普及,攻击这些模型也渐渐开始变得有利可图,其中一类攻击方式是:生成能够欺骗 AI 模型的输入,从而绕过安全过滤器。这个领域被称为对抗机器学习(AML),研究的是能针对目标模型生成对抗样本的算法。
现有的 AML 通常使用优化算法来最小化施加到输入的变化(称为扰动),使得受害者机器学习模型对带有扰动的输入进行分类时会犯错。不过,技术社区对模型防御和对抗能力的理解依然有限。
对抗样本生成算法依赖基于梯度的优化,该优化与任何其他信息无关。这些方法无法利用从以前的攻击中获得的信息来改进对其他数据的后续攻击。
这是 AML 研究中的一个空白,即研究对抗样本是否可以学习 —— 攻击的有效性和效率是否会随着经验的积累而提高。那么,对受害者模型访问权限有限(称为黑盒访问)的对手能够大规模生成对抗样本(例如分布式拒绝服务攻击)吗?
将强化学习引入对抗攻击
jrhz.info考虑到最近强化学习的成功,该团队猜想能否将 AML 对手建模为强化学习智能体 —— 这样一来,或许能让攻击策略随着时间而变得越来越高效和有效。
他们按照这个思路进行了研究,提出了基于强化学习生成对抗样本的攻击方法并对其进行了评估。
他们发现,当把对手建模成强化学习智能体时,其就能学习到哪些扰动最能欺骗模型。一旦学会了策略,对手就会使用该策略生成对抗样本。因此,对抗性智能体无需昂贵的梯度优化即可完成对模型的攻击。
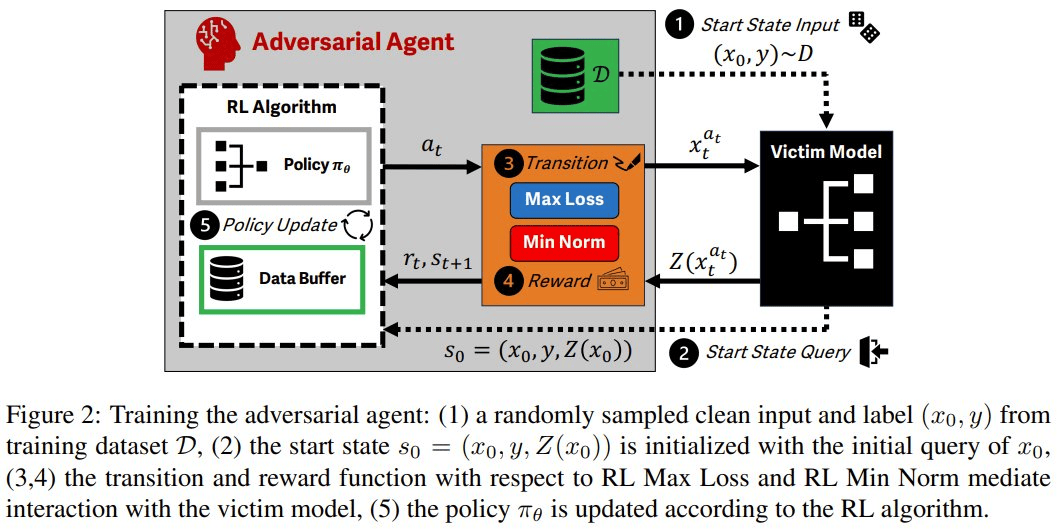
具体来说,该团队将对抗样本生成过程建模成了马尔可夫决策过程(MDP)。如此一来,便可以轻松地使用强化学习,实现对攻击的底层语义的封装:输入样本和受害者模型输出为状态,扰动为动作,对抗性目标的差异为奖励。
该团队提出了两种强化学习攻击方法:RL Max Loss 和 RL Min Norm。它们对应于两类传统的 AML 算法。

其攻击流程是这样的:首先使用一个强化学习算法来训练智能体,然后在策略评估设置中使用攻击来生成对抗样本。
实验评估
为了验证强化学习攻击方法的有效性,该团队在 CIFAR-10 图像分类任务上,使用一个 ResNet50 受害者模型进行了评估,使用的算法是近端策略优化(PPO)。该团队在此框架下进行多步骤评估,评估内容包括 (a) 学习、(b) 微调和 (c) 相对于已知方法的准确度。

首先,他们评估了强化学习智能体能否学习对抗样本。换句话说,强化学习能否在训练过程中提高对抗样本的有效性和效率?
结果发现,RL Max Loss 和 RL Min Norm 攻击都会增加训练过程中的平均回报,从而验证了强化学习技术学习任务的能力。
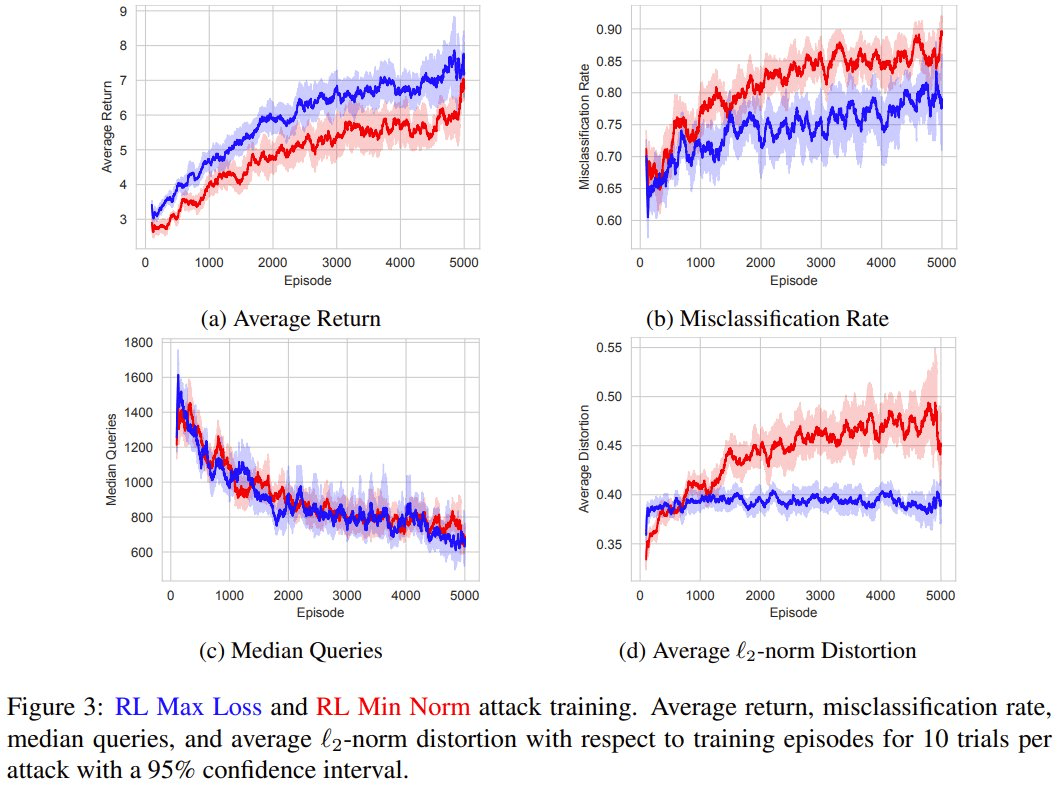
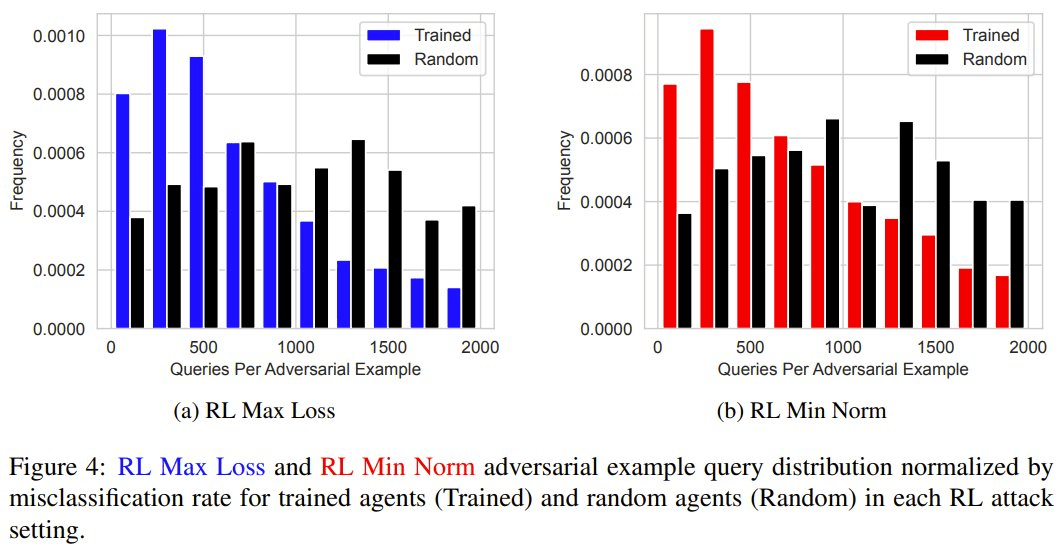
在整个训练过程中,对抗样本的产生速度平均提升了 19.4%,而与受害者模型的交互量平均减少了 53.2%。
这些结果表明,通过高效地生成更多对抗样本,智能体可在训练过程中变得更加强大。
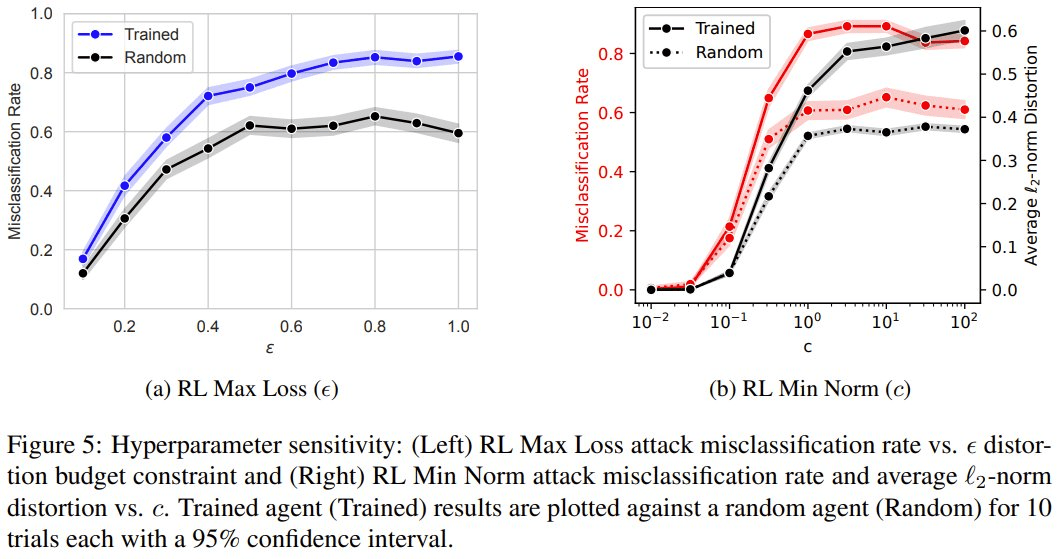
接下来,他们还分析了 RL Max Loss 和 RL Min Norm 中的奖励和转换超参数会如何影响对抗样本。
ε 参数控制的是 RL Max Loss 智能体在给定输入上允许的失真量。c 参数控制的是 RL Min Norm 智能体因降低受害者模型置信度而不是最小化失真而获得奖励的程度。
虽然训练智能体可以提高这两种攻击的性能,但他们的研究表明这也取决于 ε 和 c 的选择。具体实验中,他们根据平衡对抗性目标的敏感性分析选择了 ε = 0.5 和 c = 1.0。当对手使用这些攻击时,为了达到预期目标,必须在攻击之前考虑它们。
最后,该团队还评估了经过训练的智能体如何将对抗样本泛化到未见过的数据,以及它相对于广泛使用的基于优化的 SquareAttack 算法的表现如何。
在训练外的未见过的数据集上,训练后的智能体的错误分类率、中位数查询和对抗样本的平均失真都落在训练对抗样本的分布中。
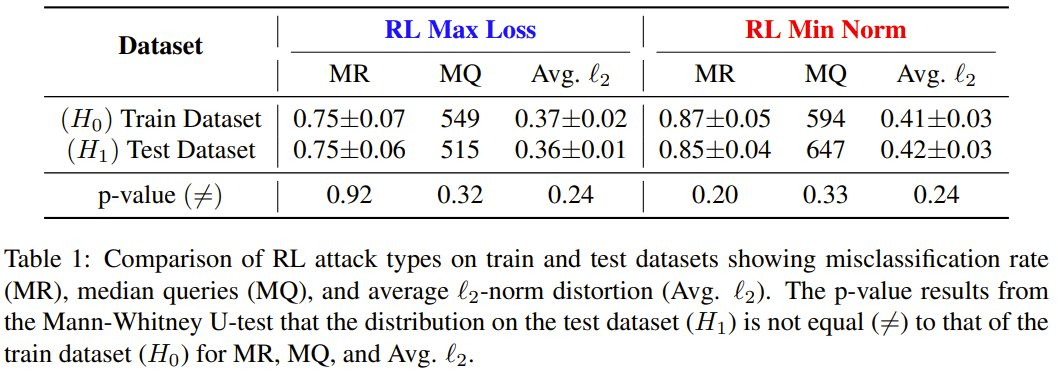
在与 SquareAttack 的黑盒比较中,他们将 5000 episode 的强化学习攻击与其它 SOTA 技术进行了比较,结果表明学习对抗样本让强化学习攻击能够生成多 13.1% 的对抗样本。
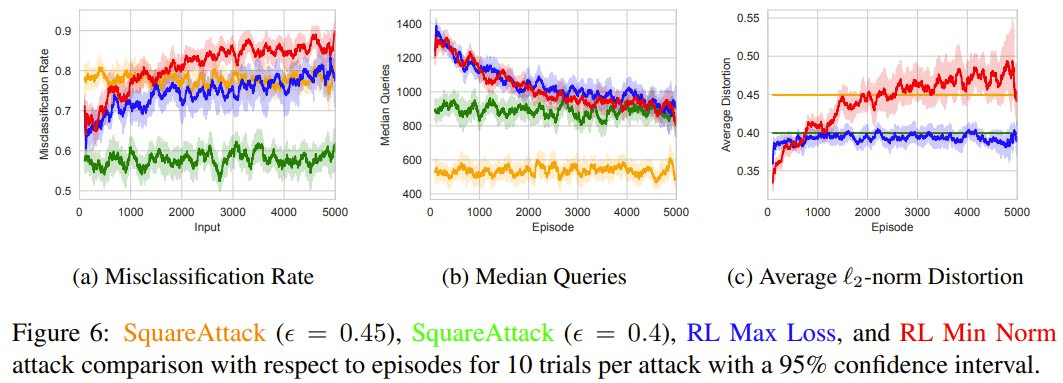
这些结果表明,如果对手通过强化学习方法学习对抗样本,会比现有方法更有效。
你怎么看待这项研究,我们又该怎么防御对手的强化学习攻击呢?




